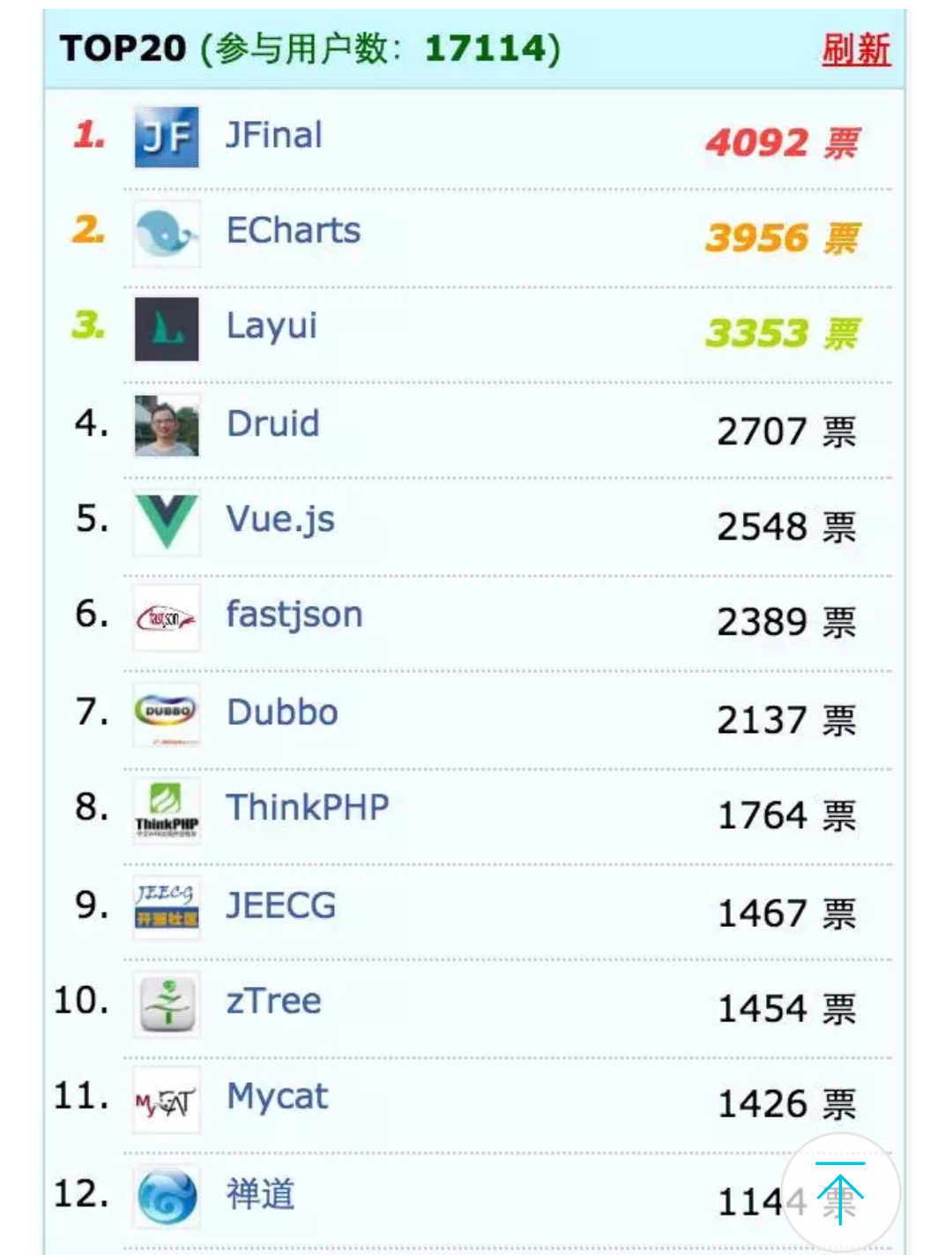
JFinal可是够火的!前三甲都用过哈!后面的好多也用过。看起来像是中国开源软件繁荣期。
JFinal可是够火的!前三甲都用过哈!后面的好多也用过。看起来像是中国开源软件繁荣期。
$(document).ready(function() { $('#example').DataTable( { "columnDefs": [ { //targets表示对哪个列生效,render是渲染方法,data是当前列的值,row是整行的数据,可以拿来引用,如果是数据源是数组,[]内填列序号,如果是对象,填字段名,一个典型应用:第0列是ID,那么可以渲染成名称,并做一个链接,把ID作为url参数
"render": function ( data, type, row ) { return data +' ('+ row[3]+')'; }, "targets": 0 }, { "visible": false, "targets": [ 3 ] } ] } );} );