Kettle转换流程中往往需要在其他步骤执行完后再执行某个步骤,但是Kettle的Transformation中的步骤设计是并行执行的,有一个方法可以打破这个流程,step: block step until steps finish。
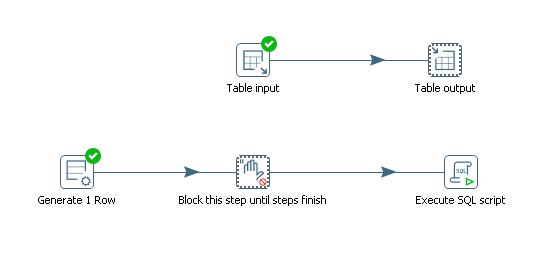
对于其他step加上它就行了,但是对于Execute SQL Script有一个特别的注意事项,如下图所示,如果不勾选这个的话,它会忽略上述流程设计。可是如果上游输入有多行的话,虽然流程生效了,但是会执行多次,这样一来,也不符合我们的要求,需要再用到另一个工具Generate rows。需要执行一次,就把limit设置为1即可。 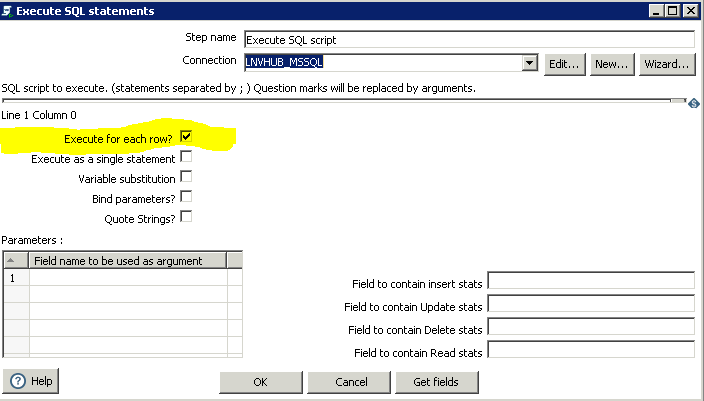
对于增量更新时的时间增量,有一个想法:1. 在源和目的数据库均保存一份时间戳offset;2. 源表转换到目标表之后,在目标数据库执行查询,查出最大时间,并把查询结果写入源数据库,3.在源数据库中编写一个函数,下次执行时where条件调用这个函数获取目标数据库已有的最大时间。
对于mysql,这个函数要有 DETERMINISTIC和READS SQL DATA这两个选项,不然查询时无法使用索引,效率会很低。
关于异构数据库之间的数据传输,如果有insert和update,建议采用临时表方式,否则数据量较大时效率会比较低,Insert/update这个step会逐条执行。不如先把有更新的数据一次性导入临时表(table output),记得加上trancat table选项,然后再目标数据库执行按主键执行delete,最后执行insert。